par1 <- as.numeric(par1) #cut off periods
par2 <- as.numeric(par2) #lambda
par3 <- as.numeric(par3) #degree of non-seasonal differencing
par4 <- as.numeric(par4) #degree of seasonal differencing
par5 <- as.numeric(par5) #seasonal period
par6 <- as.numeric(par6) #p
par7 <- as.numeric(par7) #q
par8 <- as.numeric(par8) #P
par9 <- as.numeric(par9) #Q
if (par10 == 'TRUE') par10 <- TRUE
if (par10 == 'FALSE') par10 <- FALSE
if (par2 == 0) x <- log(x)
if (par2 != 0) x <- x^par2
lx <- length(x)
first <- lx - 2*par1
nx <- lx - par1
nx1 <- nx + 1
fx <- lx - nx
if (fx < 1) {
fx <- par5
nx1 <- lx + fx - 1
first <- lx - 2*fx
}
first <- 1
if (fx < 3) fx <- round(lx/10,0)
(arima.out <- arima(x[1:nx], order=c(par6,par3,par7), seasonal=list(order=c(par8,par4,par9), period=par5), include.mean=par10, method='ML'))
(forecast <- predict(arima.out,fx))
(lb <- forecast$pred - 1.96 * forecast$se)
(ub <- forecast$pred + 1.96 * forecast$se)
if (par2 == 0) {
x <- exp(x)
forecast$pred <- exp(forecast$pred)
lb <- exp(lb)
ub <- exp(ub)
}
if (par2 != 0) {
x <- x^(1/par2)
forecast$pred <- forecast$pred^(1/par2)
lb <- lb^(1/par2)
ub <- ub^(1/par2)
}
if (par2 < 0) {
olb <- lb
lb <- ub
ub <- olb
}
(actandfor <- c(x[1:nx], forecast$pred))
(perc.se <- (ub-forecast$pred)/1.96/forecast$pred)
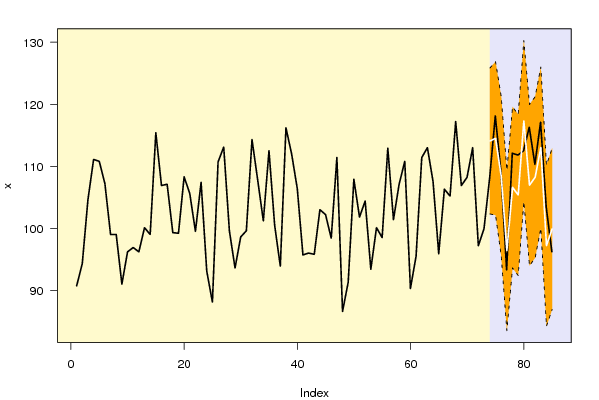
bitmap(file='test1.png')
opar <- par(mar=c(4,4,2,2),las=1)
ylim <- c( min(x[first:nx],lb), max(x[first:nx],ub))
plot(x,ylim=ylim,type='n',xlim=c(first,lx))
usr <- par('usr')
rect(usr[1],usr[3],nx+1,usr[4],border=NA,col='lemonchiffon')
rect(nx1,usr[3],usr[2],usr[4],border=NA,col='lavender')
abline(h= (-3:3)*2 , col ='gray', lty =3)
polygon( c(nx1:lx,lx:nx1), c(lb,rev(ub)), col = 'orange', lty=2,border=NA)
lines(nx1:lx, lb , lty=2)
lines(nx1:lx, ub , lty=2)
lines(x, lwd=2)
lines(nx1:lx, forecast$pred , lwd=2 , col ='white')
box()
par(opar)
dev.off()
prob.dec <- array(NA, dim=fx)
prob.sdec <- array(NA, dim=fx)
prob.ldec <- array(NA, dim=fx)
prob.pval <- array(NA, dim=fx)
perf.pe <- array(0, dim=fx)
perf.mape <- array(0, dim=fx)
perf.se <- array(0, dim=fx)
perf.mse <- array(0, dim=fx)
perf.rmse <- array(0, dim=fx)
for (i in 1:fx) {
locSD <- (ub[i] - forecast$pred[i]) / 1.96
perf.pe[i] = (x[nx+i] - forecast$pred[i]) / forecast$pred[i]
perf.mape[i] = perf.mape[i] + abs(perf.pe[i])
perf.se[i] = (x[nx+i] - forecast$pred[i])^2
perf.mse[i] = perf.mse[i] + perf.se[i]
prob.dec[i] = pnorm((x[nx+i-1] - forecast$pred[i]) / locSD)
prob.sdec[i] = pnorm((x[nx+i-par5] - forecast$pred[i]) / locSD)
prob.ldec[i] = pnorm((x[nx] - forecast$pred[i]) / locSD)
prob.pval[i] = pnorm(abs(x[nx+i] - forecast$pred[i]) / locSD)
}
perf.mape = perf.mape / fx
perf.mse = perf.mse / fx
perf.rmse = sqrt(perf.mse)
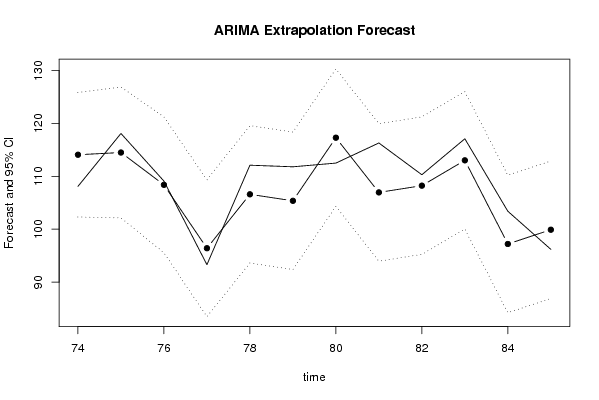
bitmap(file='test2.png')
plot(forecast$pred, pch=19, type='b',main='ARIMA Extrapolation Forecast', ylab='Forecast and 95% CI', xlab='time',ylim=c(min(lb),max(ub)))
dum <- forecast$pred
dum[1:12] <- x[(nx+1):lx]
lines(dum, lty=1)
lines(ub,lty=3)
lines(lb,lty=3)
dev.off()
load(file='createtable')
a<-table.start()
a<-table.row.start(a)
a<-table.element(a,'Univariate ARIMA Extrapolation Forecast',9,TRUE)
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'time',1,header=TRUE)
a<-table.element(a,'Y[t]',1,header=TRUE)
a<-table.element(a,'F[t]',1,header=TRUE)
a<-table.element(a,'95% LB',1,header=TRUE)
a<-table.element(a,'95% UB',1,header=TRUE)
a<-table.element(a,'p-value
(H0: Y[t] = F[t])',1,header=TRUE)
a<-table.element(a,'P(F[t]>Y[t-1])',1,header=TRUE)
a<-table.element(a,'P(F[t]>Y[t-s])',1,header=TRUE)
mylab <- paste('P(F[t]>Y[',nx,sep='')
mylab <- paste(mylab,'])',sep='')
a<-table.element(a,mylab,1,header=TRUE)
a<-table.row.end(a)
for (i in (nx-par5):nx) {
a<-table.row.start(a)
a<-table.element(a,i,header=TRUE)
a<-table.element(a,x[i])
a<-table.element(a,'-')
a<-table.element(a,'-')
a<-table.element(a,'-')
a<-table.element(a,'-')
a<-table.element(a,'-')
a<-table.element(a,'-')
a<-table.element(a,'-')
a<-table.row.end(a)
}
for (i in 1:fx) {
a<-table.row.start(a)
a<-table.element(a,nx+i,header=TRUE)
a<-table.element(a,round(x[nx+i],4))
a<-table.element(a,round(forecast$pred[i],4))
a<-table.element(a,round(lb[i],4))
a<-table.element(a,round(ub[i],4))
a<-table.element(a,round((1-prob.pval[i]),4))
a<-table.element(a,round((1-prob.dec[i]),4))
a<-table.element(a,round((1-prob.sdec[i]),4))
a<-table.element(a,round((1-prob.ldec[i]),4))
a<-table.row.end(a)
}
a<-table.end(a)
table.save(a,file='mytable.tab')
a<-table.start()
a<-table.row.start(a)
a<-table.element(a,'Univariate ARIMA Extrapolation Forecast Performance',7,TRUE)
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'time',1,header=TRUE)
a<-table.element(a,'% S.E.',1,header=TRUE)
a<-table.element(a,'PE',1,header=TRUE)
a<-table.element(a,'MAPE',1,header=TRUE)
a<-table.element(a,'Sq.E',1,header=TRUE)
a<-table.element(a,'MSE',1,header=TRUE)
a<-table.element(a,'RMSE',1,header=TRUE)
a<-table.row.end(a)
for (i in 1:fx) {
a<-table.row.start(a)
a<-table.element(a,nx+i,header=TRUE)
a<-table.element(a,round(perc.se[i],4))
a<-table.element(a,round(perf.pe[i],4))
a<-table.element(a,round(perf.mape[i],4))
a<-table.element(a,round(perf.se[i],4))
a<-table.element(a,round(perf.mse[i],4))
a<-table.element(a,round(perf.rmse[i],4))
a<-table.row.end(a)
}
a<-table.end(a)
table.save(a,file='mytable1.tab')
|