Free Statistics
of Irreproducible Research!
Description of Statistical Computation | |||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Author's title | |||||||||||||||||||||||||||||||||||||||||
| Author | *The author of this computation has been verified* | ||||||||||||||||||||||||||||||||||||||||
| R Software Module | rwasp_univariatedataseries.wasp | ||||||||||||||||||||||||||||||||||||||||
| Title produced by software | Univariate Data Series | ||||||||||||||||||||||||||||||||||||||||
| Date of computation | Mon, 01 Dec 2008 09:17:16 -0700 | ||||||||||||||||||||||||||||||||||||||||
| Cite this page as follows | Statistical Computations at FreeStatistics.org, Office for Research Development and Education, URL https://freestatistics.org/blog/index.php?v=date/2008/Dec/01/t1228148278km9346eowpaygtg.htm/, Retrieved Sat, 05 Jul 2025 18:15:05 +0000 | ||||||||||||||||||||||||||||||||||||||||
| Statistical Computations at FreeStatistics.org, Office for Research Development and Education, URL https://freestatistics.org/blog/index.php?pk=26965, Retrieved Sat, 05 Jul 2025 18:15:05 +0000 | |||||||||||||||||||||||||||||||||||||||||
| QR Codes: | |||||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||||
| Original text written by user: | |||||||||||||||||||||||||||||||||||||||||
| IsPrivate? | No (this computation is public) | ||||||||||||||||||||||||||||||||||||||||
| User-defined keywords | |||||||||||||||||||||||||||||||||||||||||
| Estimated Impact | 268 | ||||||||||||||||||||||||||||||||||||||||
Tree of Dependent Computations | |||||||||||||||||||||||||||||||||||||||||
| Family? (F = Feedback message, R = changed R code, M = changed R Module, P = changed Parameters, D = changed Data) | |||||||||||||||||||||||||||||||||||||||||
| F [Univariate Data Series] [Airline data] [2007-10-18 09:58:47] [42daae401fd3def69a25014f2252b4c2] F D [Univariate Data Series] [Q5] [2008-12-01 16:17:16] [7ed4ec9f8cdf7df79ef87b9dc09dff20] [Current] | |||||||||||||||||||||||||||||||||||||||||
| Feedback Forum | |||||||||||||||||||||||||||||||||||||||||
Post a new message | |||||||||||||||||||||||||||||||||||||||||
Dataset | |||||||||||||||||||||||||||||||||||||||||
| Dataseries X: | |||||||||||||||||||||||||||||||||||||||||
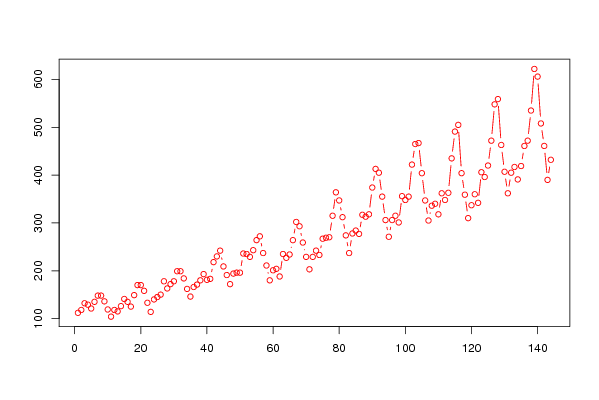
112 118 132 129 121 135 148 148 136 119 104 118 115 126 141 135 125 149 170 170 158 133 114 140 145 150 178 163 172 178 199 199 184 162 146 166 171 180 193 181 183 218 230 242 209 191 172 194 196 196 236 235 229 243 264 272 237 211 180 201 204 188 235 227 234 264 302 293 259 229 203 229 242 233 267 269 270 315 364 347 312 274 237 278 284 277 317 313 318 374 413 405 355 306 271 306 315 301 356 348 355 422 465 467 404 347 305 336 340 318 362 348 363 435 491 505 404 359 310 337 360 342 406 396 420 472 548 559 463 407 362 405 417 391 419 461 472 535 622 606 508 461 390 432 | |||||||||||||||||||||||||||||||||||||||||
Tables (Output of Computation) | |||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||
Figures (Output of Computation) | |||||||||||||||||||||||||||||||||||||||||
Input Parameters & R Code | |||||||||||||||||||||||||||||||||||||||||
| Parameters (Session): | |||||||||||||||||||||||||||||||||||||||||
| par1 = Airline ; par2 = Box-Jenkins ; par3 = Airline Passengers ; | |||||||||||||||||||||||||||||||||||||||||
| Parameters (R input): | |||||||||||||||||||||||||||||||||||||||||
| par1 = Airline ; par2 = Box-Jenkins ; par3 = Airline Passengers ; par4 = ; par5 = ; par6 = ; par7 = ; par8 = ; par9 = ; par10 = ; par11 = ; par12 = ; par13 = ; par14 = ; par15 = ; par16 = ; par17 = ; par18 = ; par19 = ; par20 = ; | |||||||||||||||||||||||||||||||||||||||||
| R code (references can be found in the software module): | |||||||||||||||||||||||||||||||||||||||||
bitmap(file='test1.png') | |||||||||||||||||||||||||||||||||||||||||